
Randomization and complete data on the randomized experimental units are needed for cause-and-effect inference. What happens when that logic is broken?
Introduction
For those who follow this blog, you may have noticed a rather long hiatus in blog entries. I have been absorbed in writing a book on cause and effect [with notable linkage to the topic of estimands and ICH E9(R1)]. But I am back to writing blogs with this first installment related to estimands. It draws from elements of my book – Does This Treatment cause That Outcome? The Science of Estimating a Treatment Effect and Why It Matters (available mid-July, 2026).
This blog and others to follow (stay tuned) will comment on some recent papers related to estimands that have appeared in the journal Statistics in Medicine. The starting point is a paper by Fleming et al (2025), which was critical of some major aspects of the ICH E9(R1) international guidance on estimands and sensitivity analysis. I will assess and critique their perspective. There are a set of three Commentaries that followed the Fleming paper in Statistics in Medicine (albeit a year later), and I will write a blog on each of those in the not-too-distant future with a similar evaluation. Finally, the last blog in this installment will be a reviedw of the Rejoinder by Fleming et al to the three Commentaries.
Before I can accomplish a meaningful critique of the perspectives of Fleming et al and the ensuing Commentaries/Rejoinder, we need some context, some history to frame the discussion of these papers. First, some history on the so-called intention-to-treat (ITT) principle, and second some history and explanation of the term “estimand.” I have chosen to write these in separate blogs of digestible length. All of this is written in the context of the ICH E9(R1) (Estimands and Sensitivity Analysis), which is the Addendum to ICH E9 (Statistical Principles for Clinical Trials). Some familiarity with those documents will ground the reader’s understanding of the concepts herein.
BUT THERE WILL BE NO (OR VERY LITTLE/SIMPLE) MATH!
So, here goes with the beginning of this series – some history of ITT.
Charles Sanders Peirce – Philosophy
I believe it is essential to understand some bits and pieces of history to understand how and why we got to the place we are today with the discussion of estimands. As sung by Maria (played by Julie Andrews) in the Sound of Music, “Let’s start at the very beginning; it’s a very good place to start.”
In 1884, Charles Sanders Peirce did the first randomized controlled experiment. (Peirce and Jastrow, 1885). At the time, this was a novel approach, and he used it to test the limits of human sensation by having subjects lift different weights and declaring whether the weights felt different or not. Now, Peirce is largely unknown in the statistical community, but he was very prominent in the world of philosophy, and some have said he is the greatest philosopher to emerge from the United States. The experiment was done in a controlled environment and the presentation of the weights by the experimenter (Peirce and his colleague Jonathan Jastrow) was governed at random by a deck of red and black cards that were shuffled. They subjected the data to analysis noting, “… the probable error of a judgment can be calculated according to the mathematical theory of errors,” which today we would recognized as something akin to a hypothesis test. As a philosopher, he recognized that randomization was a key to making causal inference.
Sir Ronald Fisher – Statistics
Decades later, the famed statistician, Sir Ronald Fisher, developed the notion of randomization at Rothamsted Experimental Station for use in agricultural fields experiments. [Note: I have not seen any connection between Fisher and Peirce, implying that Fisher’s statistical work occurred independently of Peirce’s philosophical work.] Along with the notion of experimental design, Fisher formed the theory of randomization as a mathematical basis for statistical inference. (Fisher, 1925) Fisher is widely recognized as the father of modern statistics, and his work on randomization and hypothesis testing (including the notion of the p-value) is fundamental to much scientific experimentation to this day.
Sir Austin Bradford Hill – Clinical Trials
In 1937, Sir Austin Bradford Hill, a highly respected epidemiologist and quantitative researcher, published the book Principles of Medical Statistics, in which he introduces the use of randomization for clinical trials. (Hill, 1937) Very early in that book (p.3 in fact), Hill states,
“We must endeavor to equalize the groups we compare in every possibly influential respect except in the one factor at issue – namely the … treatment.”
Here we begin to see the concept of a randomized controlled trial (RCT) emerge. On p. 8 of Hill’s book, he describes the value of randomization as creating comparable groups for study, and he coined the phrase comparing “like with like.”
But that is not enough. We must have a controlled environment to insure there are no extraneous influences that could bias the assessment of the treatment effect. Most often, the “control” in the randomized controlled trial is conceived as a control group that is treated in the same way as the experimental group. That is absolutely true. But, once again, that is not enough. There is also the requirement of a controlled environment, and in the case of Peirce it was a lab setting. For Fisher it was the agricultural fields used according to a specific experimental design (e.g., split-plot design). For clinical trialists, it is the protocol.
Complete Data
A clinical trial protocol has at its core a Schedule of Activities (SoA) that defines in exquisite detail the actions that are taken at each step of the clinical trial – what treatments/doses the patient should take (or not take), what measurements should be made, what timing is used for follow-up (e.g., weekly or monthly visits for W weeks). Ideally, patients would follow the protocol SoA completely and precisely, creating complete data for the clinical trial.
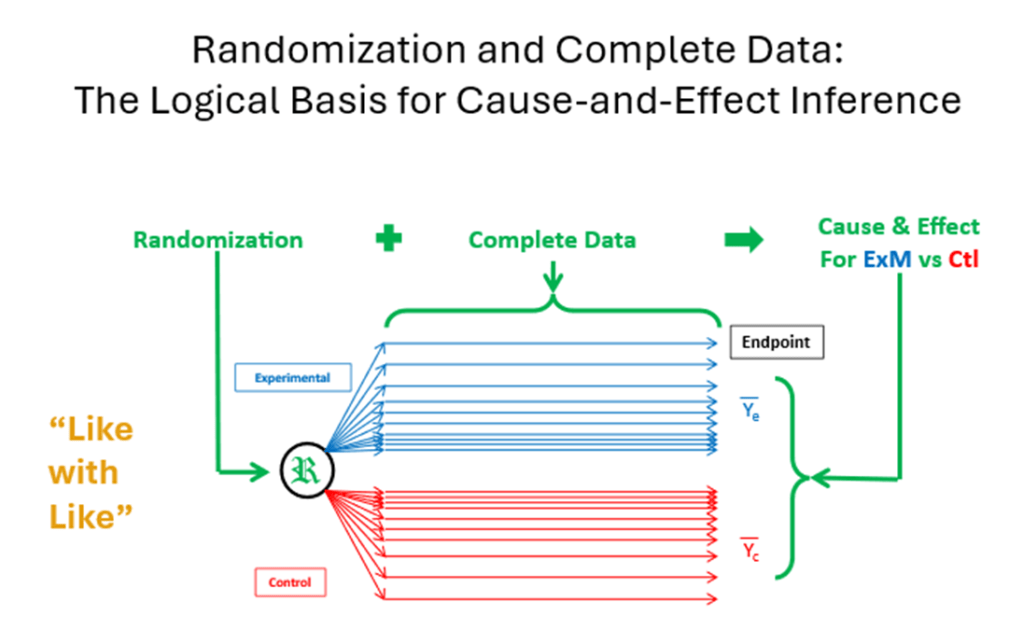
So, putting this altogether, with the balance conferred by randomization at baseline, and every randomized patient (experimental unit) following the protocol (the experimental design) to the end so that no extraneous factors could influence their response, we can compare the average responses (or some suitable summary measure) at the end of the trial. If there is a difference in the average responses between the experimental group and the control group, then we can logically say that it must be due to the experimental group (i.e., the treatment effect) since all other factors have been “equalized” (in the words of Hill). This is the basis for causal inference using statistical methods.
Randomization + Complete Data Þ Cause-and-Effect.
The notion of “complete data” is not noted explicitly in the work of Peirce and Fisher (at least that I can find). It was just a given. For Peirce, subjects were brought into the laboratory environment, and all were subjected to the simple comparison of weights. For Fisher, the agricultural fields were fixed in geographical space and were present from start to finish of the planting/growing season.
Sir Austin Bradford Hill – Clinical Trials
For Hill, this was not an issue initially. As part of the UK Medical Research Council (MRC) efforts to treat tuberculosis, he is credited with being instrumental in designing and performing the first double-blind RCT for testing streptomycin in pulmonary tuberculosis. (MRC, 1948) The trial was a resounding success, and an accompanying editorial in the BMJ noted, “The [blinded, randomization] plan adopted is worthy of careful study in itself, quite apart from the results to which it led, for it may well serve as a model in this field.”
Indeed! Over the ensuing 2-3 decades, the RCT (especially the double-blind version) became the gold standard for clinical evidence generation. As noted in 1968 by Dr. Donald Frederickson, Director of the US National Heart Institute, “The anarchy of guess and intuition [in the design and analysis of clinical trials] has given way to a benevolent tyranny of statisticians.” (Frederickson, 1968). Yeah! The statisticians won the battle for causal inference. In fact, the famous statistician Fred Mostellar said, “You can only prove causality with [randomization] statistics.” (Rosenbaum, undated lecture)
But wait! If it were only that simple.
Somewhere in the 1950’s, clinical trials started getting bigger and more complex. Hill’s initial double-blind RCT was done in an in-patient setting, but as trials grew in size and complexity and moved to outpatient settings, not every patient followed the protocol; not every patient completed the trial on their study medication; not every patient took their randomized study treatment. The balance conferred by randomization at baseline and the control induced by a common protocol were disrupted. As Miguel Hernan and colleagues note,
“Despite what you may have heard, randomized trials are not always free of confounding and selection bias. Randomized trials are expected to be free only from baseline confounding but not from post-randomization confounding and selection bias.” (Hernan et al, 2013)
Awareness of this issue appears to have been discussed in the late 1950’s, though I can find no explicit reference to it until 1961. In that year, Hill published the 7th edition of his very popular book Principles of Medical Statistics, and in it was a new section on “Differential Exclusions” in the chapter on “Clinical Trials.” In it he states,
“Before analyzing the results of a trial there is one other vital question to consider – have any patients after admission to the treated or control group been excluded from further observation? … Unless the losses are very few or therefore unimportant, we may inevitably have to keep such patients in the comparison and thus measure the intention to treat in a given way rather than the actual treatment.” [Note: The italics are his, not mine.]
Thus, was born the so-called ITT Principle, but it is a (perhaps subtle) shift from measuring the effect of the actual treatment to the effect of the intent to use the treatment. By the 1980’s, ITT was emerging as the preferred approach for analysis of RCTs, and in 1998, the ITT principle was codified into the international guidance ICH E9 Statistical Principles for Clinical Trials as the preferred approach.
ICH E9 and ITT
Experience with ICH E9 grew rapidly and globally, and in the 2000’s it was de rigueur. But statisticians and clinicians struggled with the interpretation of the treatment effects estimates it produced. [Note: It was the same struggle that clinicians had in the 1960’s when ITT emerged.] The struggle is exemplified by the following situation … and many more like it that are common in clinical trials.
Let’s say a diabetic patient is randomized to an experimental treatment (X) or control (C). A patient on X has an adverse event mid-way through a 52-week trial and is given a “rescue medication (R)” that is a known, approved, marketed anti-diabetic treatment. The patient does well on R with a notable reduction in HbA1c and acceptable safety. Using the ITT principle, that favorable outcome is attributed to X and analyze as if HbA1c that followed R was caused by X. A similar scenario could occur for patients on C; the patient fails on C and gets R and succeeds with the successful outcome being attributed to C for inference. And by the way, the R following E could be different than the R following C. Of course, this is further complicated by the fact that, inevitably, there are some patients who leave the study and for whom we cannot make a 52-week measurement of their outcome – HbA1c or safety.
Hmmm.
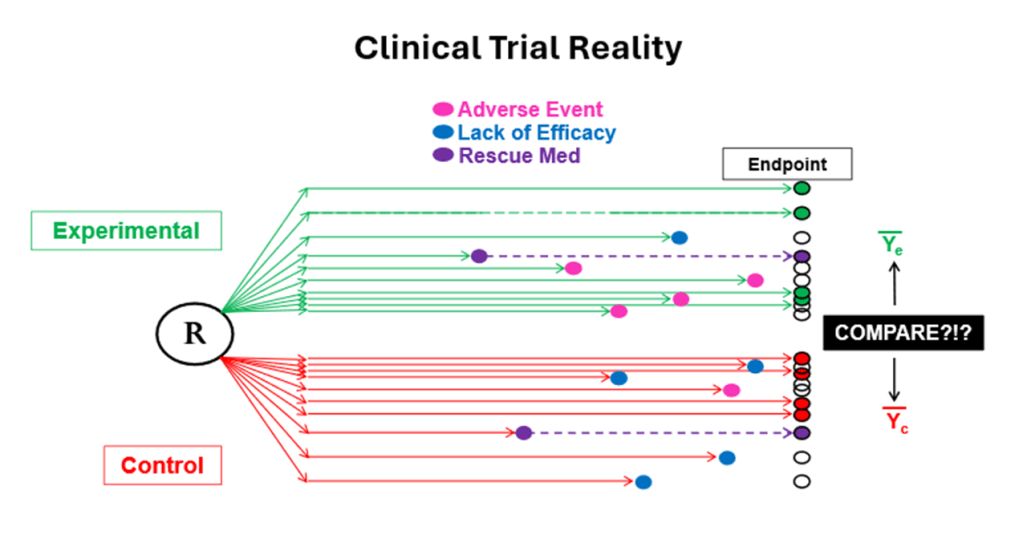
So, there is a fundamental problem of having incomplete data for all experimental units on the randomized treatments that breaks the logical basis of cause-and-effect inference regarding the randomized treatments. Randomization is intact; it is conducted flawlessly (as it is in the vast majority of trials). Incomplete data is the fundamental problem in our quest for cause-and-effect inference.
In the Purpose and Scope of ICH E9(R1), it states, “It remains undisputed that randomisation is a cornerstone of controlled clinical trials and that analysis should aim at exploiting the advantages of randomisation to the greatest extent possible. However, the question remains whether estimating an effect in accordance with the ITT principle always represents the treatment effect of greatest relevance to regulatory and clinical decision making.” [Note: my bold emphasis added.]
The historical story is presented in more detail in my aforementioned book with examples, quotes, references etc. that explain how ITT became the preferred approach for clinical trials – not only for pharma and new drug development, but for academic and government funded clinical trials as well.
In the next blog, I will describe how the term “estimand” has exploded into our discussions about clinical trials and statistical matters in the last decade. Stay tuned.
References
Fleming TR, Carroll KJ, Wittes JT, Emerson SS, Rothmann MD, Collins S, Levin G. A Perspective on the Appropriate Implementation of ICH E9(R1) Addendum Strategies for Handling Intercurrent Events. Stat Med. 2025 May;44(10-12).
Charles Sanders Peirce & Joseph Jastrow (1885). On Small Differences in Sensation. First published in Memoirs of the National Academy of Sciences, 3, 73-83. (Presented 17 October 1884).
Fisher, R. A. Statistical Methods for Research Workers. (Oliver & Boyd, Edinburgh, 1925).
A. Bradford Hill. Principles of Medical Statistics. London: Lancet, 1937.
Medical Research Council. Streptomycin treatment of pulmonary tuberculosis. BMJ. 1948;2:769–782.
Frederickson DS, “The field trial: some thoughts on the indispensable ordeal.” Bulletin of the New York Academy of Medicine, Vol. 44, No. 8, August 1968.
Experiments & Observational Studies: Causal Inference in Statistics. Lecture by Paul R. Rosenbaum, Department of Statistics, University of Pennsylvania Philadelphia, PA.
http://www-stat.wharton.upenn.edu/~rosenbap/ExperAndObsTalk.pdf (Accessed 10/20/2024)
Hernán, M. A., Hernández-Díaz, S., Robins, J. M. Randomized trials analyzed as observational studies. Ann Intern Med. 2013 October 15; 159(8).
