I read an interesting article because the title was so provocative: “What if AI in health care is the next asbestos?” It’s a great article as well as being a quick read.
Artificial intelligence (AI) continues to be touted a solution to many problems. Of course, AI can mean so many different things to people. In my pharma career (and this was within the last couple of years), I saw “analytics” companies boast of their machine learning (ML) and AI capabilities that they could sell to us (at a handsome price), only for us to look under the hood and, in one case, see stepwise logistic regression! One simple question “Do you prefer forward selection or backward elimination?” was enough to set them on their heels and out of the room without a contract.
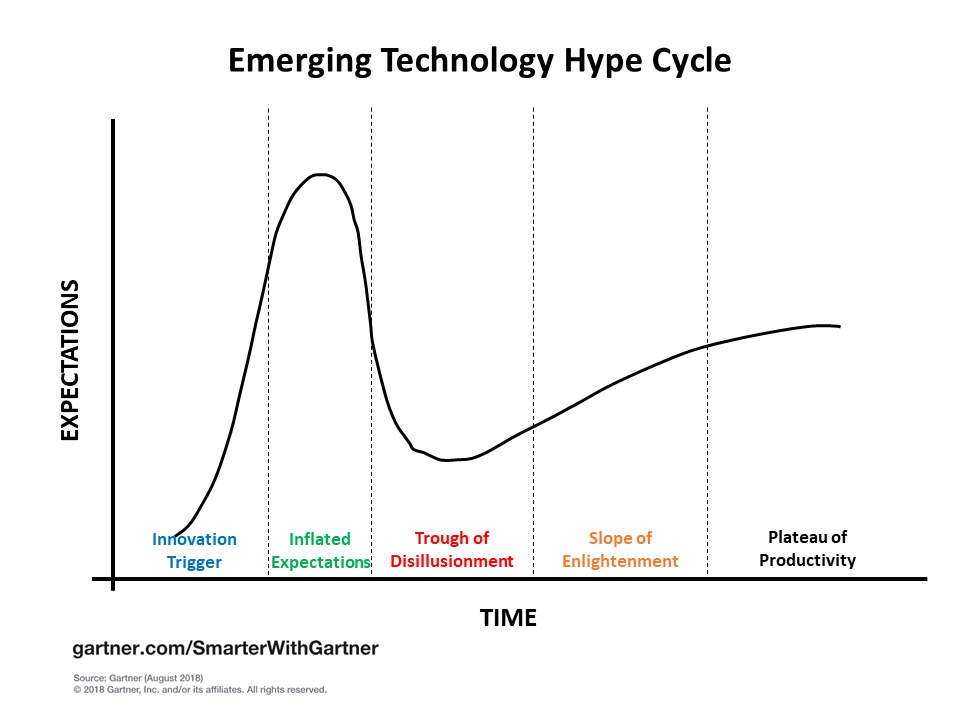
There is some growing skepticism that AI is not a panacea, skepticism that is well-founded as noted in the above article. It reminds me of the description by Gartner (the consulting company) when they described the “Emerging Technology Hype Cycle” (see Figure). It is difficult to say where we are on this cycle with AI, perhaps because AI seems to defy a uniform description. Furthermore, some aspects of science and business seem to be making notable productivity gains (albeit perhaps using some rather standard analytical tools and methods) while others are still over-hyping AI without a clear understanding of what it is, as noted above.
For me, AI must have some form of reinforcement learning. That is, the algorithm(s) behind the AI system must be able to update themselves based on accumulating data or experience. See for example the 17-minute lecture by Demis Hassibis at Deep Mind (https://www.youtube.com/watch?v=rbsqaJwpu6A). I find that only recently are those involved with developing AI systems beginning to think about or understand the issues with bias.
First, there may be bias in data. After all, all models are developed or trained on data and the training dataset used for creating an AI system (i.e. algorithms) are crucial. I have heard many stories of how deep learning using neural networks can fail miserably because of this data bias. One intentional example to make this point comes from ““Why Should I Trust You? Explaining the Predictions of Any Classifier” (https://arxiv.org/pdf/1602.04938v3.pdf). One person described an example in the paper succinctly.
“Neural networks are designed to learn like the human brain, but we have to be careful. … we must make sure machines learn correctly. One example … is how one neural network learned to differentiate between dogs and wolves. It didn’t learn the differences between dogs and wolves, but instead learned that wolves were on snow in their picture and dogs were on grass. It learned to differentiate the two animals by looking at snow and grass. Obviously, the network learned incorrectly. What if the dog was on snow and the wolf was on grass? Then, it would be wrong.”
Another kind of bias is the subtle or difficult to detect/quantify bias that comes from human beings deciding what is important to put in a model and what can be left out. Furthermore, for most algorithms, there is some quantity being optimized, and humans decide what the goal of the algorithm is by defining what that quantity is. I found the book Weapons of Math Destruction by Cathy O’Neil very interesting in this regard. She cites her own experiences as a data scientist as well as provides many examples of how human biases have negatively impacted (a) ranking of colleges and universities in U.S News and World Report, (b) teacher evaluations, (c) sentencing guidelines for convicted criminals and more. She notes:
- “… models, despite their reputation for impartiality, reflect the goals and ideology [of the modeler].”
- “Models are opinions embedded in mathematics.”
- “… we must ask not only who designed the model but also what that person or company was trying to accomplish.”
I hope that data scientists are given rigorous training in detecting bias in data or other inputs into a model. Statisticians are trained a bit more on the topic of bias, but bias can be subtle and difficult to identify. The key is to be a bit skeptical and, before engaging in any analysis or model building, lead with questions such as:
- Where did the data come from?
- How was it collected?
- Was data collected on everyone or everything, or only a subset?
Gee, the phrase is trite and has been overused in the past, but it still applies today: “Garbage in; garbage out.”
